
“你也喜欢迪士尼系列动画及原创故事吗? 2019年开始,你不再需要到处找资源,花贵贵的钱到电影院,或是特别订阅Netflix才能看到了!因为迪士尼即将推出他们自有的影音串流平台『Disney Play』,收录的内容包含旗下的动画及收回原在Netflix 播放的漫威系列、皮克斯内容,改由自有平台播送。 “

科技打開您更多想像



Netflix 能窜起成为世界首屈一指,提供多媒体影音串流服务的OTT(Over The Top) 业者绝非侥幸,它已经凭借着精细、准确的巨量数据分析,成功地从单纯提供网路串流影音服务跨到影音内容制作,绝对是网路影音时代的成功典范。
Netflix 于1997 年在美国加州成立,然而当时提供的并不是多媒体影音串流服务,而是DVD 租赁服务,在当时提供DVD 租赁最知名的是现在已经谢幕的百视达(BlockBuster),百视达当时采取的是消费者自行到实体门市取片与还片的模式,然而Netflix 却完全舍弃实体通路,而推出会员订阅制,顾客每个月支付月租费后,直接在网站上从数万部的影片库中,选取并列出想看的影片清单,Netflix 会依照不同月租费费率,寄出数量不等的DVD 给顾客,等顾客把DVD 寄还后,再寄出清单上的其它DVD 。
虽然会员订阅制大获成功,2007 年甚至宣布第10 亿张出租DVD 的惊人数字,但是著眼于DVD 租赁市场即将饱和,以及网路速度提升后网路影音服务的潜力,Netflix 在同年也宣布启动多媒体影音串流服务,2010 年从邻居加拿大开始,将触角从美国伸向海外,并陆续进军欧洲与亚洲市场,截至2016 年10 月为止,已经在超过190 个国家提供服务,订阅会员超过8,600 万,Netflix 在2011 年3 月起,更从单纯的影音串流服务平台业者,跨足内容生产领域,推出纸牌屋(House of Cards)影集后一炮而红,成为Netflix 的招牌作品。
根据最新一季的统计资料,Netflix 在2016 年Q3 的会员数增加了350 万,并且创造了有史来最佳的季度营收22 亿美金,其中有40% 都是来自美国以外的市场,Netflix 的成功不只来自具竞争力的订价(美国地区月费最低8 美金起跳),方便的即选即看模式,甚至是成功的行销策略,更重要的是它巨细靡遗的巨量数据分析带来的影片推荐系统。
在Netflix 仍只是提供DVD 租赁业务时,唯一能掌握的使用者喜好资料,只有每次使用者填写的影片星数评比,这也是当时Netflix 优化推荐系统的唯一数据,然而,在开始进入多媒体影音串流服务后,就开始有了大量的数据可以进行分析,例如使用者看了什么,使用者怎么看的(哪种装置、几点钟看的、星期几看的、一次会看多久),点选Netflix 的页面上哪个地方的影片,甚至哪些推荐影片是完全没被点过的等,这些数据以及这些数据分析出来的结果都被用来让Netflix 预测使用者究竟想看什么影片。
当使用者开始登入Netflix 观赏影片的时候,Netflix 就会将一个观看(view)记录在资料系统内,并且利用各种事件(events)来描述这个观看行为,也就是使用者从订阅开始,产生的每一个行为,都会被纪录成事件,包括使用者的搜寻、评分、观看地点、装置资讯、浏览Netflix 网站行为、时间、日期,或者是快转、暂停,以及观看地点,装置资讯,其它第三方资讯,甚至是社群网站资料。
在Netflix 的网站的隐私权声明,详述了所收集的资讯:
我们收到和储存您的资讯,如:
您向我们提供的资讯:我们收集您向我们提供的资讯包括:
您的姓名、电邮地址、住址或邮递区号、、付费方式和电话号码。我们通过多种方式收集这些资讯,包括您使用我们的服务时输入的资讯、与我们的客户服务互动或参与调查或促销活动时输入的资讯;以及
在您选择撰写评论或评分、爱好设定、帐户设定、设置「您的帐户」偏好或以其他方式通过我们的服务或在其他地方向我们提供资讯时,收集到的资讯。
我们自动收集的资讯:我们收集有关您、您使用我们的服务、与我们的互动及您使用我们广告的资讯,以及有关您使用电脑或其他装置(如:游戏系统、智慧型电视、行动装置和机上盒)存取我们的服务的资讯。这些资讯包括:
您在 Netflix 服务的动态,如:标题选择、观看历史和搜索查询;
有关您与客户服务互动的详情,例如:您联系我们的日期、时间和原因、任何聊天对话记录以及您致电联系我们时的电话号码;
装置 ID 或唯一识别码,装置和软体的特点(如:类型和配置)、连接资讯、网页查看、推荐 URL、IP 位址和标准网路日志资讯统计;
通过使用 Cookie、网路信标与其他技术而收集的资讯,包括广告资料(如:传输至 Cookie 的页面印象资讯、页面印象传输的网站 URL 以及日期和时间)。如需更多详情,请参阅 Cookie 与网际网路广告章节。
从其他来源获取的资讯:我们可能用从其他来源获取的资讯(包括来自线上和离线资料提供者的资讯)补充上述资讯。此类补充资讯可能包括人口资料、基于兴趣的资料和网际网路浏览行为。
收集的资讯使用在何种用途,也注明在「资讯使用」一节:
我们使用所收集的资讯来提供、分析、管理、提升我们的服务和行销工作,使我们的服务和行销工作个人化,处理您的注册、您的订单和支付,并与您就这些主题和其他主题进行沟通交流。例如,我们把所收集的资讯用于:
判定您的大致地理位置、以当地语言提供内容、向您提供客制化和个人化观影推荐、推荐您我们觉得您会喜欢的电影与节目、判定您的网际网路服务提供者以及帮助我们迅速有效率地回应您的询问及要求;
防止、监测和调查潜在的被禁止或非法
活动(包括诈欺),以及执行我们的条款(如:决定免费试用资格);
分析和了解我们的观众;改进我们的服务(包括我们的使用者介面体验)、传输最佳化、内容选择和推荐演算法;
与您沟通交流我们的服务(例如:通过电邮、推送通知和简讯),以便我们可以向您发送有关Netflix 公司的资讯、Netflix 新功能和内容的详情、特别优惠、促销消息和消费者调查,并协助您办理密码重设等操作请求。请参阅本隐私权声明的「您的选择」章节,了解如何设置或更改您的通讯偏好设定。
使用者这次的观看花了多少时间,资料系统就要持续记录过程中发生的所有事件,因此就需要一个强大且具扩充性的资料平台架构才能处理这么庞大的资料,而这也是Netflix 能成功的最重要关键。
根据统计,Netflix 数据平台每天接收的资料约1.3PB 资料( 约5000亿次事件),如果是在尖峰时段,则是每秒约24GB 资料(800 万次事件)),因此免不了一定是采用Hadoop 平台架构处理,并且一定要持续在扩充容量,然而Netflix 的Hadoop 平台,和传统以资料中心为基础的Hadoop 平台不同,Netflix 直接在云端上建立了一个几乎拥有无限储存空间且无限运算能力的资料仓储( data warehouse)。
一般的Hadoop 平台架构,其档案都是储存在Hadoop 分散式档案系统(Hadoop Distributed File System, HDFS),Hadoop 分散式档案系统可以在一般的商用硬体上面运作,并且对大型资料集提供容错与高通量存取,因此多数公司的传统作法,都是将资料仓储建立在云端Hadoop 集群上的Hadoop 分散式档案系统。然而,Netflix 却是选择把资料储存在亚玛逊云端服务( Amazon Web Service, AWS)S3 上。
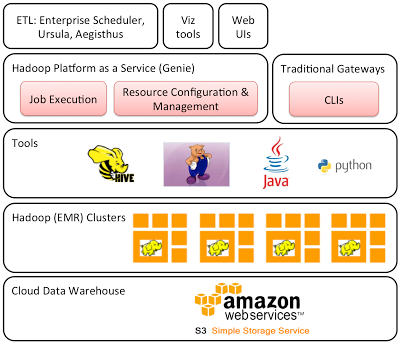
▲Netflix 的 Hadoop 平台架构图(资料来源:Hadoop Platform as a Service in the Cloud)
架构图中最底层的 S3 是用来储存所有值得保存的资料集,包括每个小时从 Netflix 服务上传过来的数十亿计的各种事件,以及其它的维度资料(dimension data)。 S3 保证具有99.999999999% 的持续性(dutality),以及99.99% 的可用性(availability),能够容许两个装置同时损失资料;同时也可以允许存在多版本资料,使用者不小心误删就可以将资料回复;S3 也具有可以随时无限扩充的弹性,不需要替未来的资料预留储存空间;S3 也可以同时运作多个、高度动态集群。
Netflix 在处理巨量数据上,则是采用Amazon’s Elastic MapReduce (EMR) distribution,这是一种能够简易地快速及低成本的处理大量资料的网路服务,用来针对同样一批资料,同时启动多个Hadoop 集群来处理不同的工作负载(workloads)。在Netflix 的Hadoop 架构的工具层里,使用了Hive 来处理即时查询(ad hoc queries)与分析(analytics),用Pig 处理ETL 跟演算法,以Vanilla java 为基础的MapReduce 也偶尔用来处理复杂的演算法,Python 则用来制作脚本。
Netflix 在工具层之上则采用了 Genie,这是它们自建的 Hasoop 平台即服务,让Netflix 可以方便的在 Hadoop 环境中进行工作处理与资源调度。下一篇将会介绍Netflix如何利用这些数据达成精准的推荐系统。
Follow 我们的Page,每天追踪科技新闻!
想看更多英文版文章吗? 点我进去~